Statistik
- Maße
- Mittelwert: x¯=n1∑inxi
- Stichprobe: sxy=n−11∑i(xi−x¯)(yi−y¯)
- Stichprobenvarianz sx2=n−11∑i(xi−x¯)2
- Varianz: var(X)=E[(X−E(X))2]
- Standardabweichung: σX=sX=√var(X)
- Kovarianz: cov(X,Y)=E[(X−E(X))(Y−E(Y))]=E(XY)−E(X)E(Y) (anderes Maß für Korrelation)
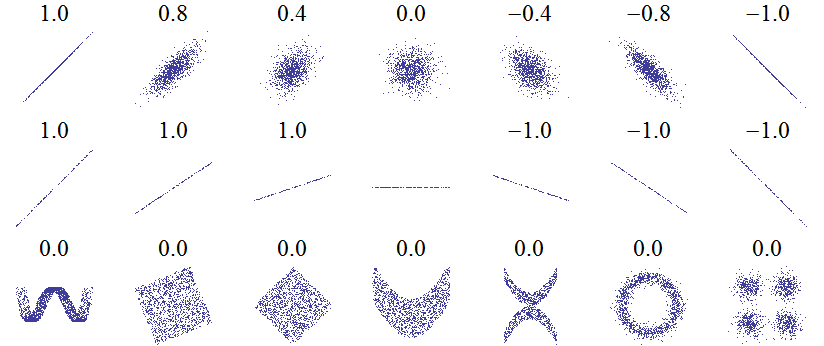
- Pearsons Korrelationskoeffizienten r=√var(X)var(Y)cov(X,Y),−1≤r≤1
- Empirischer Korrelationskoeffizient: R=sxsysxy (Schätzung für r)
- Regeln
- var(X)=cov(X,X)
- var(X+Y)=var(X)+var(Y)+2cov(X,Y) (Kovarianz ist Ausgleichsterm für Additivität der Varianz)
- r=0⇒ X und Y unkorreliert, X und Y unabhängig ⇒r=0
- Korrelation
- R: (A+C) / (B+D) = R, hoch: R positiv, niedrig: R negativ
- oder: A + D >> B + C: pos, B + C >> A + D (C | D, A | B)
Regressionsanalyse
y^=b0+b1x1+…+bpxp+e
- y: abhängig, x: unabhängig, bi: Modellparameter, e: Fehlervariable
- Annahmen: en normalverteilt, E(en)=0,var(en)=σ2,cov(em,en)=0,m≠n
- Minimiere: SAQ(b0,b1)=∑i=1N(yi−b0−b1xi)2
- b0=y¯−b1x¯,b1=∑i=1Nxi2−nx¯2∑i=1Nxiyi−nx¯y¯
- SQT: erklärende Abweichungen (SQE + SQR), SQE: erklärte, SQR: nichterklärte
- Bestimmtheitsmaß: r2=SQTSQE,SQE=∑i=1N(y^i−y¯)2,SQT=∑i=1N(yi−y¯)2
- 0: keine Erklärung, 1: vollständige Erklärung
- Lineare logistische Regression
- abh. Variable Y ist binär
- Rechne mit Wsk p=P(Y=1)⇒0≤p≤1
- Betrachte Chance: P(Y=0)P(Y=1)=1−pp
- Logit-Funktion: logit(p)=ln(1−pp)=b0+b1X=z⇒p=1+ezez
- nur approxmierbar (zB. Maximum-Likelihood)
Testverfahren
- Signifikanzniveau α, krititscher Wert c, Effektgröße γ
- einseitig oder zweiseitig
- Vorgehen
- Aufstellung von H0 und HA und Festlegung von α
- Festlegung geeigneter Prüfgröße und Testverteilungsbestimmung
- Bestimmung des kritischen Bereichs
- Berechnung des Wertes der Prüfgröße
- Entscheidung + Interpretation
- Zusammenhänge
- α+⇒β− (höhere Güte)
- (μ0−μA)+⇒β− (höhere Güte)
- n+∣∣σ2−⇒(1−β)+
- ES- ⇒ Güte-
- t-Test
- parametrisch, Gleichheit der Erwartungswerte
- Voraussetzungen: Normalverteilung (Varianz unbekannt)
- T=SX¯−μ0√n (T Student-t-verteilt)
- falls Varianz bekannt: Z=σX¯−μ0√n
- überschätzt / ist aggressiv
- F-Test für Gleichheit der Varianzen
|
H0 wahr |
H0 falsch |
| H0 ablehnen |
α (1. Art) |
1−β (Güte / Trennschärfe) |
| H0 annehmen |
1−α |
β (2. Art) |
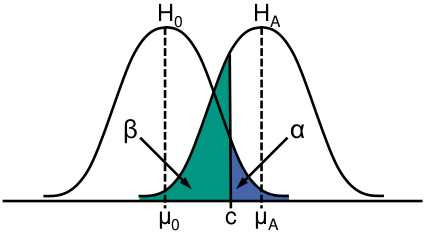
Güteananalyse
- 4 Parameter: α,1−β,n,γ (aus 3 ist der 4. berechenbar)
- n: vor Expirement, ES schätzen mit Pilotstudie / vergl. Expiremnt, Grundlage für Hypothesentest
- Güte: für Korrekturen am Expirementaufbau (=Wsk selbes Ergebnis)
- ES: Maß für Vergleich von Studien (γ=σμx−μy, 0.2(klein), 0.5(mittel), 0.8 (groß))
- α: ungewöhnlich (meist n und Güte)
- Standardwerte: α=0.05,β=0.2 (+schätze ES --> berechne n)
- Auswertung: nur falls Hypothese nicht abgelehnt (bei geringer Güte wird kleiner Effekt angenommen)
- Probleme
- Overpowered: zu viele Daten --> kleine, uninteressante Effekte haben Einfluss
- Underpowered: zu wenige Daten --> Effekt nur mit geringer Wsk zeigbar
- Wilcoxon-Test braucht im wc 0.8641 mehr Datenpunkte als t-Test (selbe Güte)
Wilcoxon-Rangsummentest
- nicht parametrisch (keine Ann. über Parameter der Verteilung), Zweistichproben-Test, Gegenstück zum t-Test
- Überprüfung ob Stichproben selbe Verteilung besitzen (keine Normalverteilungsannahme)
- Voraussetzungen: X, Y unab., haben stetige Verteilungsfunktionen F, G
- Hypothesen: H0:F(z)=G(z),H1:∀z∈R,θ≠0:F(z−θ)=G(z)
- F, G selbe Form, aber mögl. verschoben
- F, G normalverteilt --> t-Test (Erwartungswert) + F-Test (Varianz)
- Vorgehen
- Beob. X (Länge m), Y (Länge n), m≤n,N=m+n
- Kombiniere Stichproben + sortiere
- Vergebe Ränge 1 bis N (bei gleichem Wert, verwende Mittelwert)
- Summiere die Ränge von X: WN=∑i=1NiVi
- Wähle α + Teste H0: lehne ab, falls WN≤w (je nach ein- oder zweiseitiger Test)